
Arquitectura Big Data III: Fase de Procesamiento. ¿ Cómo cocino mis datos para obtener un plato de calidad?
En este post y siguiendo el flujo de fases generales que consta una arquitectura de Big Data, nos centraremos en la fase de “Procesamiento” de los datos recolectados en la anterior fase (sino lo has leído aquí lo tienes).
Antes de entrar en materia, comentar que esta fase también la podemos encontrar con otros nombres, como por ejemplo “Transformación”, “Análisis y modelaje”, etc, pero el contenido es el mismo.
Empecemos.
Debemos partir de una base muy importante, en todo proyecto donde puedan participar soluciones Big Data, para identificar dichas soluciones requeridas, primero de todo debemos plantearnos una arquitectura lógica, lo cual quiere decir que la forma de como construimos una arquitectura con tecnología Big Data, es siguiendo el proceso de la transformación de los datos, dónde el Big Data va a ser la ´fuente´ de este proceso el cual influenciará en las distintas fases hasta llegar al consumidor o persona que recibe el resultado de la transformación.
Pensemos que de la transformación depende en gran medida, que el dato resultante sea de calidad y estratégico, para proporcionar la información requerida que ayude a alcanzar los objetivos establecidos, casi nada!
Es por eso que esta fase a comentar, hay que pensarla y diseñarla muy bien, teniendo claro los objetivos y otros que puedan influenciar en su totalidad.
Para intentar visualizarlo mejor, pondremos el siguiente ejemplo antes de entrar en materia:
Imagínate que hemos salido con nuestro barco y hemos capturado varios peces (fase de recolección ya explicada) y seguidamente los peces capturados los llevamos a nuestro restaurante para prepararlos.
Una vez en la cocina del restaurante (Staging Área), nos tenemos que encargar de preparar los pescados (fase actual de procesamiento) según exigencias del chef (reglas de negocio), como por ejemplo, limpiar los pescados capturados sacándolos las escamas y otros, cortarlos en piezas según requerimiento del plato a elaborar, … (Transformación) para después el chef pueda elaborar, con esas piezas ya transformadas, los diferentes platos de la mejor forma posible (Análisis), potenciando su sabor.
Visto esto de una forma más simple, pasemos a ver la fase de procesamiento a un nivel más técnico.
¿Por dónde empezamos?
Empecemos por saber bien que es lo que realiza en concreto esta fase, porque al tener una parte de transformación y otra de análisis, a veces esta línea es tan fina y estrecha, que da lugar a confusiones, un poco más adelante y visto lo expuesto a continuación, lo detallaré un poco más.
Entonces en esta fase tenemos dos grupos de tareas:
1. Transformación ( limpieza y otras tareas a realizar sobre las piezas pescadas):
En esta tarea se aplican una serie de reglas de negocio o funciones, anteriormente definidas por negocio, sobre los datos en bruto recolectados (extraídos en la anterior fase), para adaptarlos y convertirlos en datos que estén en línea con la estrategia a seguir con el objetivo que aporten el valor real de la información.
Por ejemplo, en esta tarea se realizan las tareas de perfilado de datos (limpieza), como parte de la calidad de estos establecidos por negocio.
¡Pero cuidado!
En esta fase, dónde debemos de definir la lógica de calidad de los datos, no la podemos realizar igual que en las estructuras de Business Intelligence tradicionales, utilizando base de datos estructuras, donde cuando creábamos la estructura de estas, ya podíamos definir las reglas de calidad, como por ejemplo, cómo se iban a almacenar los datos, los tipos de datos, si puede ser nulo, si es único, etc, esto se llama esquema de escritura (schema on write), pero cuando trabajamos en diseños con Big Data, generalmente no usamos bases de datos relacionales, sino que estas suelen ser del tipo NoSQL , ya que dadas sus características en la forma de guardar los datos de una forma más “libre” y no estructurada en un inicio, se integran mejor a las exigencias del guion en referencia a la funcionalidad de la solución, es por eso que se trabaja en esquema de lectura (schema on read), lo cual significa que no podemos definir las reglas de negocio por ejemplo de calidad, a nivel de la base de datos, sino que lo deberemos de realizar a un nivel de capa de aplicación, resumiendo, la calidad de los datos se realiza diferente a lo que estábamos acostumbrados hasta hace poco.
2. Análisis ( cómo vamos a cocinar los pescados ya limpiados y preparados en base a las exigencias del chef):
Una de las actividades que ocurren en este pueden ser, análisis de texto, análisis predictivos, data mining, etc.
Aquí, es donde sacamos el valor de los datos ya trasformados, mediante técnicas de Data Analytics, que nos proporcione información táctica y estratégica a representar.
Hay que tener presente, que esta parte del análisis no tendrá ningún sentido si la etapa anterior de transformación, no se ha realizado correctamente en todo sus niveles, imagínate elaborar un plato con las piezas no limpiadas, se quejaran seguro.
¿Pero los datos se procesan igual?
Depende de las necesidades del proyecto y tipos de respuestas, me explico, puede haber proyectos que necesiten por ejemplo, procesar los datos de forma programada una o dos veces al día, pero hay otros que necesitan de una fase de procesamiento continuo, es decir, tal como se extraen los dato, se deben procesar.
Esta diferencia de funcionalidad, hace que se distingan dos niveles de procesamiento:
a. Proceso en Tiempo Real (Streaming Processing): es el procesamiento que nos permite, tan pronto como los datos son capturados, van siendo procesados en un flujo continuo.
Las principales tecnologías para esto, las podemos clasificar en el modo de su procesamiento en dos grupos:
- Full-Streaming: Apache Storm, Apache Samza, Apache Flink, …
- Microbatch: Spark Streaming, Storm Trident …
b. Proceso por lotes (Batch Processing): como hemos comentado, este proceso se realiza de forma periódica, sin necesidad de procesar los datos de forma continua.
Son procesos que trabajan con grandes volúmenes de información y se basa para su ejecución en el paradigma MapReduce que nos ofrece Apache Hadoop.
Pero hay algunos inconvenientes en este tipo de procesos, que con el tiempo, se están mejorando, de forma:
- Inconveniente de programación costosa:
Programar a nivel de MapReduce para según qué procesos complejos, es muy costoso de realizar, es por eso que han surgido algunas soluciones que se pueden aplicar en Apache Hadoop, que proporcionan capas de extracciones a más alto nivel para cubrir este inconveniente, como Apache Hive (HiveSQL), Cascading (Java),…
- Inconveniente de procesos lentos:
MapReduce trabaja bien con grandes cantidades de datos, pero puede ser lento ya que necesita escribir en disco en sus diferentes fases, para solucionar este inconveniente, han surgido tecnologías como Apache Tez, Apache Spark (este puede trabajar tanto en streaming processing como en batch processing), …
¿Cuál es la mejor opción de procesamiento?
Esto dependerá del tipo de necesidades de la solución a desarrollar, pero una cosa que quede clara, estos dos tipos de procesamiento, pueden coexistir en la misma solución, por ejemplo para una plataforma de recomendaciones online, se puede utilizar una arquitectura lambda, donde se ejecutan los dos tipos de procesos, veamos cómo, de una forma general, sin entrar en la tecnología a utilizar:
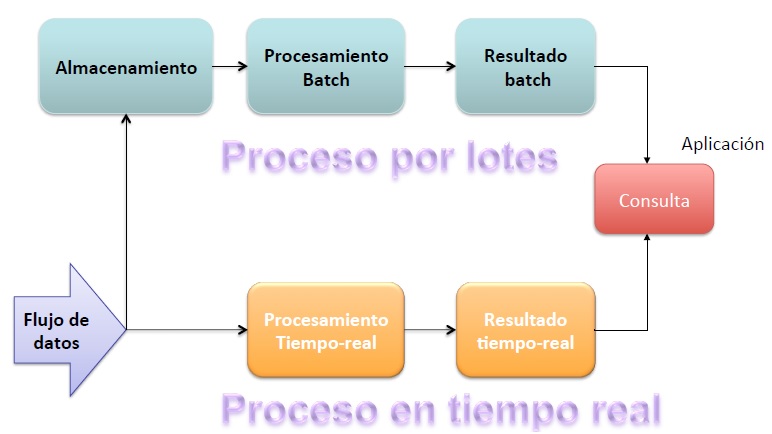
¿Cómo va esto?
Imaginemos que necesitamos saber, mediante las visitas de usuarios (logs) que han ido visitando o comprando en nuestra plataforma online, el histórico de sus visitas y lo que están visitando en ese momento, para poderles recomendar a estos usuarios, diferentes productos mientras están visitando.
Para ello necesitamos que a medida que van llegando estos logs de visita, los vaya almacenando para obtener el histórico de estas, para ello utilizaremos la parte de Proceso por lotes refrescando la información por ejemplo una vez al día, y por otro lado los irá analizando los logs conforme van entrando, para ello utilizaremos la parte de proceso en Tiempo Real o Streaming proceessing, donde los resultados se van refrescando cada minuto.
Por lo tanto, estamos procesando los mismos datos de dos formas distintas porque así lo especifica la necesidad de la solución, en este caso por ejemplo, el de saber el histórico de visitas del usuario en los últimos 4 meses al mismo tiempo que se navega, de forma que se generen recomendaciones en base a tu histórico de visitas conjuntamente con las recomendaciones en base al cálculo de visitas de las últimas tres horas.
Me queda claro, pero ¿porque has dicho antes que la fase de procesamiento da lugar a confusión?
Si, tienes razón, esto es un punto importante a aclarar.
Procesamiento y Análisis de los datos, son dos conceptos distintos pero a la vez van de la mano, la principal diferencia es a nivel de complejidad, es difícil trazar una línea que diga dónde termina uno y empieza el otro.
El procesamiento lo podemos ver más como una transformación y el análisis más como una extracción de un valor no visible de forma simple, a partir de la transformación.
Pongamos un ejemplo para poderlo ver mejor:
Apache Hive y MapReduce son herramientas en principio para transformar los datos, estas transformaciones pueden ser simples y/o complejas, por lo que se podría confirmar que estas sirven para transformar y analizar en función de esta complejidad.
Apache Hive por ejemplo, permite el uso de las UDF (User Define Functions) para realizar análisis más complejos a nivel de batch processing.
Apache Spark Streaming es una plataforma de transformación y análisis en tiempo real, la cual nos permite programar a más alto nivel mediante lenguajes como Python o Scala.
Pero hay que tener en cuenta que hay otras herramientas de transformación y análisis que están fuera del ecosistema Hadoop, que también nos permiten realizar esta fase, como por ejemplo SaS o R Studio.
En resumen, las herramientas dependiendo de su complejidad, tienen cabida en esta fase a nivel de transformación, análisis o ambos.
El objetivo es que el plato elaborado a partir de esas piezas pescadas, se puedan presentar al comensal según las expectativas del restaurante, aportando valor a este.
Cristian Anguera.